シーザー暗号というものをご存知でしょうか。
平文の各文字を、n文字分シフトさせて作る暗号です。
例えば、”hello”という文字列を1文字シフトさせると”ifmmp”になります。
1文字ぐらいなら頭の中で計算できますが、13文字分ずらすといった処理は面倒ですよね。
シーザー暗号の中でも、シフト数を13にした方式はROT13として有名です。
アルファベットが26文字なので、暗号化と複合が同じ変換でできるからです。
今回はシーザー暗号を解読するためのプログラムをPythonで組んでみます。
ROT13はPythonに実装されている
PythonにはROT13が実装されているので、13文字分のシフトであればすぐに出力できます。
codecsをインポートして、デコード(またはエンコード)するだけです。
import codecs
print(codecs.decode('Hello', 'rot13'))このコードを実行すると”Uryyb”が返ってきます。
しかし、シーザー暗号がすべて13文字シフトするとは限らないですよね。
何文字シフトさせるか親切に教えてくれるわけありません。
なので、1~25文字シフトさせた文字列をすべて出力するプログラムを組むことにしました。
シーザー暗号を解読するコード
# coding: UTF-8
def rot(data):
for i in range(25):
for j in range(len(data)):
code = ord(data[j]) + 1
if code <= 122:
data = data[:j] + chr(code) + data[j+1:]
else:
data = data[:j] + chr(code - 26) + data[j+1:]
print(data)
if __name__ == '__main__':
data = input('文字列:')
data = data.lower()
rot(data)ordを使って文字をアスキーコードに変換し、+1することにしました。
chrでアスキーコードから文字へ戻すことができます。
アスキーコードに変換するとアルファベットは’a’の97から始まって’z’の122までの数値になります。
‘z’を超えたものは’a’に戻るので、123以上になったものは-26してから文字に戻すように処理を分けました。
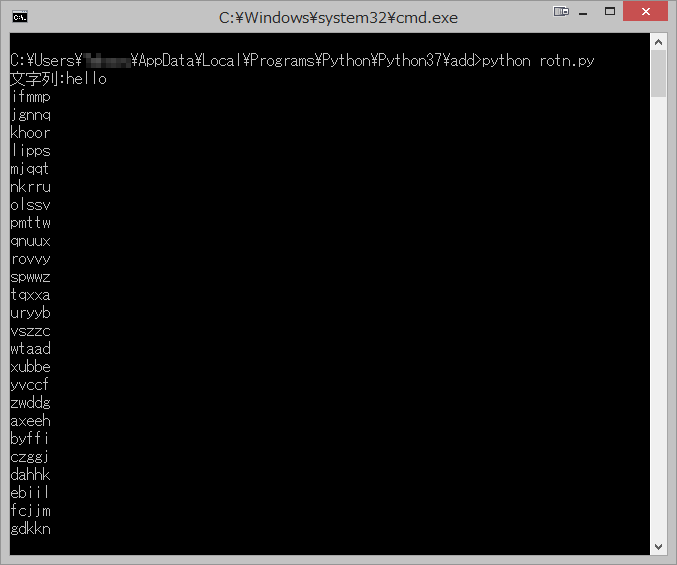
コマンドプロンプトから実行して文字列を入力すると、25パターンの文字列が一気に表示されます。
短い文字列なら、一度の入力ですべて確認できるため便利ではないでしょうか。

追記:使い勝手が悪かったので改善した
僕が書いた上のコード、実際にCTFの練習問題で使ってみました。
すると思ったより使い勝手が悪かったです。
問題になったのは下記の2点。
- すべて小文字に変換してしまう
- アルファベット以外もシフトしてしまう。
小文字に統一すると人間は読めてもデータとしては別物になってしまうので、コピペして使えず不便でした。
また、{}や_もシフトしてしまうのも問題があります。
if文を書き換えて使いやすいよう改善しました。
# coding: UTF-8
def rot(data):
for i in range(25):
for j in range(len(data)):
code = ord(data[j])
sw = 0
if code >= 65 and code <= 90:
sw = 1
elif code >= 97 and code <= 122:
sw = 2
if sw == 1 and code < 90 or sw == 2 and code < 122:
data = data[:j] + chr(code + 1) + data[j+1:]
elif sw == 1 or sw == 2:
data = data[:j] + chr(code - 25) + data[j+1:]
print(data)
if __name__ == '__main__':
data = input('文字列:')
rot(data)
“QWLR{NEQ_Mprtyypc}”という文字列を入力すると、このように出力されます。

“FLAG{CTF_Beginner}”という意味のある文字列が現れていることが確認できますね。
これなら出てきたデータをそのままコピーして他の場所で使えます。